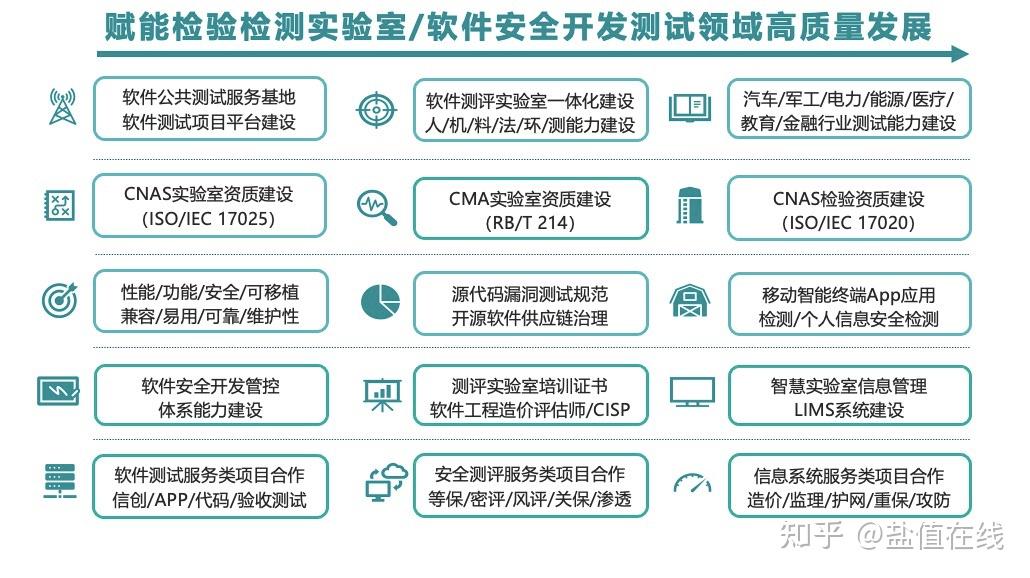
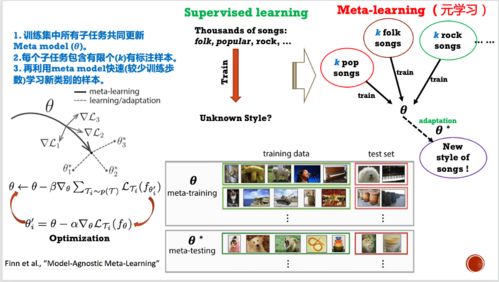
《2018中国人工智能开源软件发展白皮书》(以下简称《白皮书》)系统梳理了当时中国AI开源生态的格局、挑战与机遇,为人工智能应用软件的开发指明了重要的技术方向与产业路径。其核心结论与配套解读PPT对开发者与企业而言,是一份宝贵的“实战地图”。
一、《白皮书》核心洞察:生态崛起与关键挑战
《白皮书》明确指出,2018年前后,中国AI开源软件生态已进入快速发展期,呈现出以下特征:
- 框架层“双雄并立”:以百度飞桨(PaddlePaddle)和一流科技OneFlow等为代表的国产深度学习框架开始崭露头角,旨在打破TensorFlow和PyTorch的垄断,构建自主可控的技术底座。
- 应用层繁荣与碎片化:在计算机视觉、自然语言处理、语音识别等领域涌现出大量高质量开源项目与工具包(如旷视科技的MegEngine、商汤的OpenMMLab早期项目等),极大降低了AI技术应用门槛,但也存在重复建设、生态分散的问题。
- 产学研协同深化:高校、科研机构与科技企业共同成为开源贡献的主力,推动创新从实验室向产业界快速转化。
- 关键挑战:包括底层核心技术(如AI编译器、算力芯片)依赖度高、开源治理与社区运营经验不足、开源与商业化的平衡难题等。
二、对人工智能应用软件开发的启示与实践路径
结合《白皮书》的研判,AI应用软件开发在技术选型、流程优化和生态融入上,应遵循以下实践路径:
1. 技术选型:拥抱开源,但需战略考量
- 框架选择:评估项目需求、团队技能与长期维护成本。对于追求快速原型和丰富社区资源的项目,PyTorch/TensorFlow仍是安全选择;对于有特定性能优化需求或希望融入国产化技术栈的项目,可积极探索飞桨等国内框架。
- “工具箱”思维:积极采用成熟的开源模型库(如Hugging Face Transformers、PaddleHub)、数据预处理工具和评估基准,避免重复造轮子,聚焦业务逻辑创新。
2. 开发流程:从“模型中心”到“工程化与数据驱动”
- MLOps初步实践:借鉴开源MLOps工具链(如MLflow、Kubeflow),建立模型版本管理、自动化训练与部署流水线,提升AI软件的可重复性和可维护性。
- 数据治理优先:开源软件解决了算法工具问题,但高质量、领域特定的数据仍是核心竞争力。开发初期需建立规范的数据标注、版本管理与隐私保护机制。
3. 生态融入:参与贡献,构建长期优势
- 上游贡献:在解决自身业务问题的过程中,若对开源项目有优化或扩展,可考虑回馈社区。这不仅提升技术影响力,也能获得更早的技术支持与反馈。
- 关注“开源标准”:积极参与或关注国内AI开源标准、评测基准的建设,确保软件符合未来互联互通与合规性要求。
4. 架构设计:注重可解释性、安全与部署弹性
- 可解释性集成:利用开源可解释AI工具(如SHAP、LIME),在关键决策应用中构建透明、可信的AI功能模块。
- 安全与隐私:整合联邦学习、差分隐私等开源安全框架,应对日益严格的数据监管要求。
- 云边端协同:设计支持模型轻量化(利用开源剪枝、量化工具)和灵活部署的架构,以适应从云端服务器到边缘设备的不同场景。
三、
尽管《2018白皮书》反映的是数年前的产业快照,但其揭示的趋势——开源化降低技术门槛、国产化寻求自主可控、工程化成为落地关键——至今仍在深刻塑造AI应用开发领域。对于当代开发者而言,核心启示在于:精通主流开源工具是基础,深刻理解业务与数据是核心,而积极参与生态、构建工程化能力则是实现差异化与可持续创新的关键。 将开源软件的强大能力与扎实的软件工程实践相结合,方能打造出真正稳健、高效且有价值的人工智能应用软件。